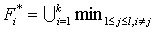A SURVEY OF RECENT ABSTRACT SUMMARIZATION TECHNIQUES
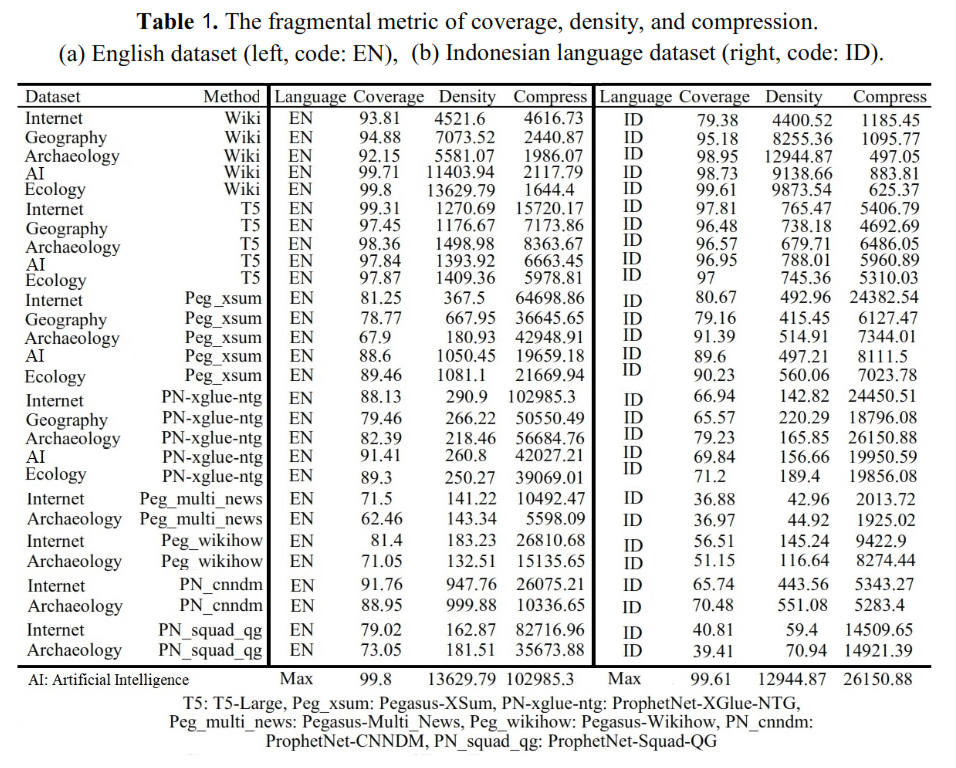
In this study (published 2022; accepted), we investigate the impact of some recent abstract summarization techniques (one T5, three Pegasuses, three ProphetNets) on several Wikipedia datasets in English and Indonesian language and compare the results to the Wikipedia systems' summaries. The T5-Large, the Pegasus-XSum, and the ProphetNet-CNNDM provide the best summarization.
The most significant factors that influence ROUGE performance are coverage, density, and compression.
Other factors that influence the ROUGE scores are the pre-training goal, the dataset's characteristics, the dataset used for testing the pre-trained model, and the cross-lingual function. Several suggestions to improve this paper's limitation are:
assure that the dataset used for the pre-training model must sufficiently large, contains adequate instances for handling cross-lingual purpose;
Advanced process (finetuning) shall be reasonable.
We recommend using the large dataset consists of comprehensive coverage of topics from many languages before implementing advanced processes such as the train-infer-train procedure to the zero-shot translation in the training stage of the pre-training model.
[1] Cheng, J., Dong, L., Lapata, M.: Long short-term memory-networks for machine reading. arXiv preprint arXiv:1601.06733 (2016).
[2] Dong, L., Yang, N., Wang, W., Wei, F., Liu, X., Wang, Y., Gao, J., Zhou, M., Hon, H.-W.: Unified language model pre-training for natural language understanding and generation. arXiv preprint arXiv:1905.03197 (2019).
[3] Fabbri, A., Li, I., She, T., Li, S., Radev, D.: Multinews: A large-scale multi-document sum-marization dataset and abstractive hierarchical model. In: Proceedings of the 57th Annual Meeting of the ACL, pp. 1074–1084, Florence, Italy (2019).
[4] Grusky, M., Naaman, M., Artzi, Y.: NEWSROOM: A Dataset of 1.3 Million Summaries with Diverse Extractive Strategies. In: Proc. Of NAACL-HLT 2018, pp. 708-719 (2018).
[5] Hermann, K. M., Kocisky, T., Grefenstette, E., Espeholt, L., Kay, W., Suleymen, M., Blun-som, P.: Teaching machines to read and comprehend. In: Advances in neural information processing systems, pp. 1693-1701 (2015).
[6] Koupaee, M., Wang, W. Y.: Wikihow: A large scale text summarization dataset. arXiv pre-print arXiv:1810.09305 (2018).
[7] Lakew, S. M., Lotito, Q. F., Negri, M., Turchi, M., Federico, M.: Improving Zero-Shot Translation of Low-Resource Languages. arXiv preprint arXiv:1811.01389v1 (2018).
[8] Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., Stoyanov, V., Zettlemoyer, L.: Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv: 1910.13461 (2019).
[9] Liang, Y., Duan, N., Gong, Y., Wu, N., Guo, F., Qi, W., Gong, M., Shou, L., Jiang, D., Cao, G., Fan, X., Zhang, R., Agrawal, R., Cui, E., Wei, S., Bharti, T., Qiao, Y., Chen, J.-H., Wu, W., Liu, S., Yang, F., Campos, D., Majumder, R., Zhou, M.: XGLUE: A New Benchmark Dataset for Cross-lingual Pre-training, Understanding and Generation. arXiv preprint arXiv: 2004.01401 (2020).
[10] Lin, C.-Y.: ROUGE: A Package for Automatic Evaluation of Summaries. In: Text summari-zation branches out, pp. 74-81. ACL, Barcelona, Spain (2004).
[11] Narayan, S., Cohen, S. B., Lapata, M. Don’t give me the details, just the summary! Topic-aware convolutional neural networks for extreme summarization. In: Proceedings of the 2018 Conference on EMNLP, pp. 1797-1807. ACL, Brussels, Belgium (2018).
[12] Qi, W., Yan, Y., Gong, Y., Liu, D., Duan, N., Chen, J., Zhang, R., Zhou, M.: ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training. arXiv preprint arXiv:2001.04063v3 (2020).
[13] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research 21, 1-67 (2019).
[14] Rajpurkar, P., Zhang, J., Lopyrev, K., Liang, P.: SQuAD: 100,000+ Questions for Machine Comprehension of Text. arXiv preprint arXiv:1606.05250 (2016).
[16] Song, K., Tan, X., Qin, T., Lu, J., Liu, T.-Y.: MASS: Masked sequence to sequence pre-training for language generation. arXiv preprint arXiv:1905.02450 (2019).
[17] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., Polosukhin, I.: Attention is all you need. In: Proceedings of the 31st International Confer-ence on NIPS, pp. 6000–6010. NIPS 2017, Long Beach, CA (2017).
[18] Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., Bowman, S.: GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. ICLR (2018). In: Proceedings of the 2018 EMNLP, pp. 353-355. ACL, Brussels, Belgium (2018).
[19] Zhang, J., Zhao, Y., Saleh, M., Liu, P. J.: PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization. In: Proceedings of the 37th International Confer-ence on Machine Learning, pp. 11328-11339. PMLR 119, Vienna, Austria (2020).
IMPROVING PERFORMANCE OF RELATION EXTRACTION ALGORITHM VIA LEVELED ADVERSARIAL PCNN AND DATABASE EXPANSION
This study (2019) introduces database expansion using the Minimum Description Length (MDL) algorithm to expand the database for better relation extraction. Different from other previous relation extraction researches, our method improves system performance by expanding data. The goal of database expansion, together with a robust deep learning classifier, is to diminish wrong labels due to the incomplete or not found nature of relation instances in the relation database (e.g., Freebase).
Actually, there are two issues: 1) database expansion method: rule generation by allowing step sizes on selected strong semantic of most similar itemsets with aims to find entity pair for generating instances, 2) a better classifier model for relation extraction.
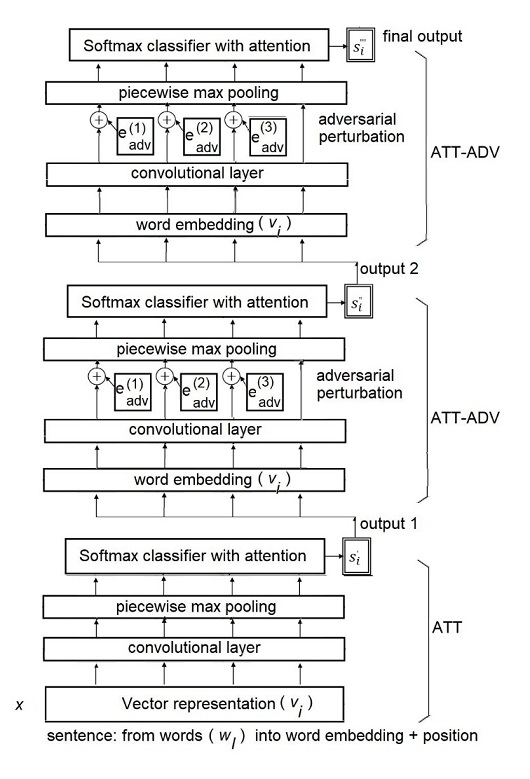
The study uses a deep learning method (Piecewise Convolutional Neural Network or PCNN) as the base classifier of our proposed approach: the leveled adversarial attention neural networks (LATTADV-ATT).
In the database expansion process, the semantic entity identification is used to enlarge new instances using the most similar itemsets of the most common patterns of the data to get its pairs of entities.
Consider a set of patterns in CT, the expanded pattern generated from k-topmost similar of most frequent itemsets defined by:
where we will do expansion by combining the maximum top-k most similar and frequent itemsets until a pair of recognized entities are found and acceptable according to the defined semantic rules. The text similarity technique from the base itemset is measured using either the cosine similarity or the Jaccard similarity. There are three kinds of situations about frequent itemsets that KRIMP generates from a sentence:
• Ideal: The ideal itemset of Fi* is a situation where an itemset (a collection of essential keywords of a sentence) has an entity pair inside. If the situation found, the itemset is appended to the database to expand the existing data.
• Half ideal: Another situation is the half ideal itemset. This kind of situation is when a pair of entities is found only a half in Fi*, thus creating an incomplete pair. This situation needs an expansion process of k-topmost similar pattern generation until Fi* has at least one entity pair inside. If there is no entity pair found in Fi* after the combination of k-topmost similar itemset, then Fi* is skipped away, and the base itemset is set up with the next item set.
• Not ideal: This is the situation when no entity found in the itemset. We skip this type of itemset since the expansion method never uses a not ideal code as a base itemset.
About the deep learning method, the use of attention of selective sentences in PCNN can reduce noisy sentences. Also, the use of adversarial perturbation training is useful to improve the robustness of system performance. The performance even further is improved using a combination of leveled strategy and database expansion.
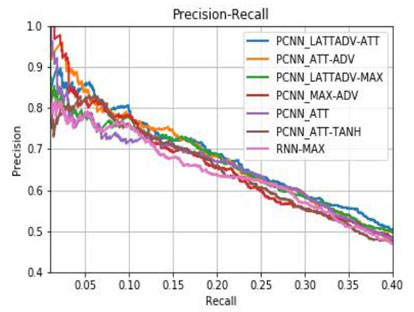
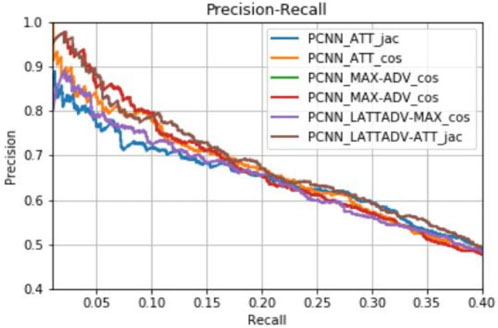
Here is the classification performance without doing the database expansion:
and here is the classification performance after we applied the database expansion:
The experimental result has shown that the use of the database expansion is beneficial. The MDL database expansion helps improvements in all methods compared to the unexpanded method. The LATTADV-ATT performs as a good classifier with high precision P@100=0.842 (at no expansion). It is even better while implemented on the expansion data with P@100=0.891 (at expansion factor k=7).
[1] C. Nogueira dos Santos, B. Xiang, and B. Zhou, “Classifying Relations by Ranking with Convolutional Neural Networks,” in ACL (1), 2015. [The 53rd Annual Meeting of the Association for Computational Linguistics, Beijing, China, pp.626–634, 2015].
2] I.J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and Harnessing Adversarial Examples,” CoRR abs/1412.6572: 2014.
[3] R. Hoffmann, C. Zhang, X. Ling, L. Zettlemoyer, and D.S. Weld, “Knowledge-Based Weak Supervision for Information Extraction of Overlapping Relations,” in HLT’11(1). Association for Computational Linguistics, Stroudsburg, PA, USA, pp.541–550, 2011.
[4] Y. Lin, S. Shen, Z. Liu, H. Luan, and M. Sun, “Neural Relation Extraction with Selective Attention over Instances,” in Proceedings of the 54th Annual Meeting of ACL(Vol. 1: Long Papers). Association for Computational Linguistics, pp.2124–2133, 2016.
[5] T. Liu, K. Wang, B. Chang, and Z. Sui, “A Soft-label Method for Noise-tolerant Distantly Supervised Relation Extraction,” in Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, pp.1790–1795, 2017.
[6] M. Mintz, S. Bills, R. Snow, and D. Jurafsky, “Distant Supervision for Relation Extraction Without Labeled Data,” in Proceedings of ACL’09: Vol.2-Vol.2 (ACL’09). Association for Computational Linguistics, Stroudsburg, PA, USA, pp.1003–1011, 2009.
[7] D. Puspitaningrum, “Patterns, Models, and Queries,” Ph.D. Dissertation. Department of Information and Computing Sciences, Utrecht University, 2012.
[8] D. Puspitaningrum, Fauzi, J.A. Pagua, et.al., “An MDL-Based Frequent Itemset Hierarchical Clustering Technique to Improve Query Search Results of an Individual Search Engine,” in Information Retrieval Technology, G. Zuccon, S. Geva, H. Joho, F. Scholer, A. Sun, and P. Zhang (Eds.). Springer International Publishing, Cham, pp.279–291, 2015.
[9] S. Riedel, L. Yao, and A. McCallum, “Modeling Relations and Their Mentions Without Labeled Text,” in Proceedings of the 2010 ECML PKDD: Part III (ECML PKDD’10), Berlin, Heidelberg: Springer-Verlag, pp.148–163, 2010.
[10] O. Sampson and M.R. Berthold, “Widened KRIMP: Better Performance through Diverse Parallelism,” in Advances in Intelligent Data Analysis XIII, Hendrik Blockeel, Matthijs van Leeuwen, and Veronica Vinciotti (Eds.), Switzerland: Springer, pp.276–285, 2014.
[11] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A Simple Way to Prevent Neural Networks from Overfitting,” in Journal of Machine Learning Research, 15, 1, pp.1929–1958, Jan 2014.
[12] M. Surdeanu, J. Tibshirani, R. Nallapati, and C.D. Manning, “Multi-instance Multi-label Learning for Relation Extraction,” in Proceedings of the EMNLP-CoNLL’12. Stroudsburg, PA, USA: Association for Computational Linguistics, pp.455–465, 2012.
[13] M. van Leeuwen and D. Puspitaningrum, “Improving Tag Recommendation Using Few Associations,” in Advances in Intelligent Data Analysis XI, Jaakko Hollmén, Frank Klawonn, and Allan Tucker (Eds.). Berlin, Heidelberg: Springer, pp.184–194, 2012.
[14] M. van Leeuwen, J. Vreeken, and A. Siebes, “Compression Picks Item Sets That Matter,” in Knowledge Discovery in Databases: PKDD 2006, J. Fürnkranz, T. Scheffer, and M. Spiliopoulou (Eds.). Berlin, Heidelberg: Springer, pp.585–592, 2006.
[15] Y. Wu, D. Bamman, and S. Russell, “Adversarial Training for Relation Extraction,” in Proceedings of the 2017 Conference on Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, pp. 1778–1783, 2017.
[16] D. Zeng, K. Liu, Y. Chen, and J. Zhao, “Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks,” in EMNLP, L. Marquez, C. Callison-Burch, J. Su, D. Pighin, and Y. Marton, Eds. Association for Computational Linguistics, pp. 1753–1762, 2015.